Index File Formats
Lucene의 주요 개념은 다음 세 가지이다.
- Index: Document의 집합
- Document: Field의 집합
- Field: 이름이 명명된 Term의 집합, Term: 문자열
Field, Term에 대한 정의가 조금 헷갈려서, 스택오버플로우의 어떤 글을 읽어봤다. 관계형 데이터베이스에 비유하면, Field는 컬럼, Term은 컬럼에 해당하는 값이다. Lucene 공식문서의 classic query parser 파트 에서는 아래와 같은 예시를 통해 이해를 도와주고 있다.
title: "The Right Way"
text: "go"
위 인덱스는 두 개의 필드를 포함하고 있다.
- title
- text
역색인(Inverted Indexing)
효율적인 term 기반의 검색을 위해 인덱스는 term의 통계 정보를 저장한다. Lucene의 인덱스는 역인덱스라고 알려진 인덱스 계열에 속한다.
안녕하세요 Elasticsearch를 이용해서 개발하고 있는 검색 개발자입니다.
Elasticsearch를 배우고 싶은 쥬니어 개발자입니다.
쥬니어 개발자는 검색 개발시 Elasticsearch를 이용하면 좋나요?
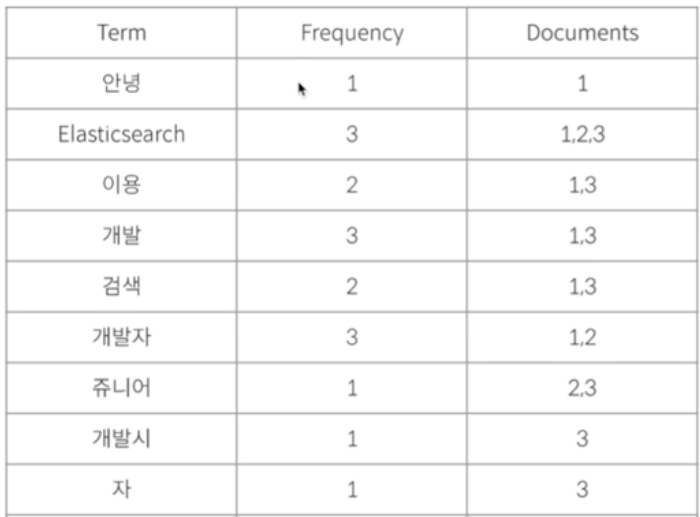
“Elasticsearch”라는 term이 등장한 문서를 찾는다고 생각해보자. 연인덱스 구조를 하고 있는 위 표에서 아주 쉽고 빠르게 찾을 수 있다.
세그먼트(Segments)
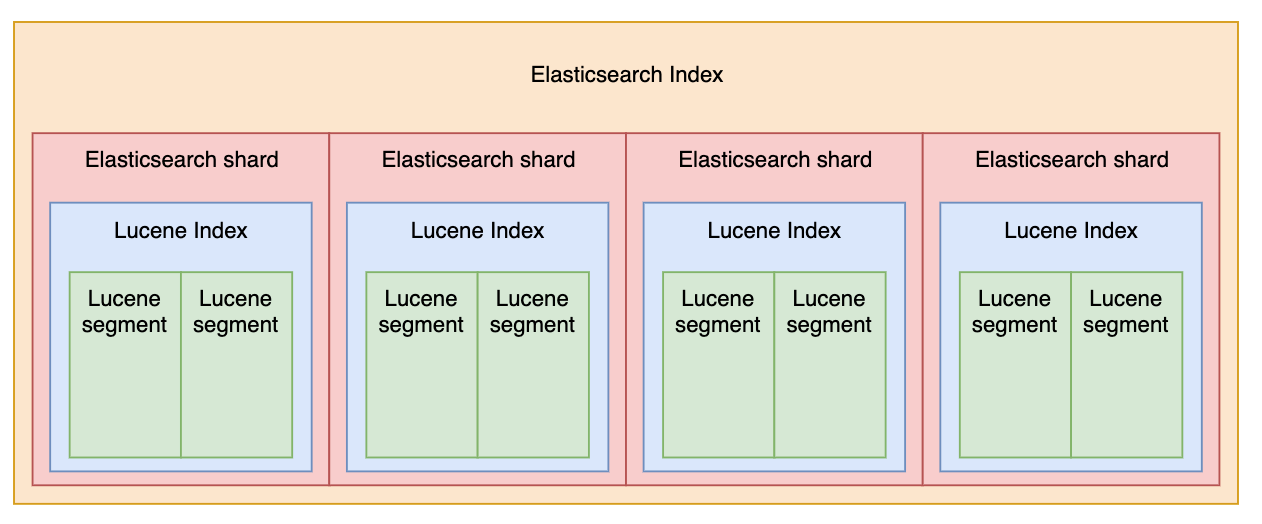
Lucene의 인덱스는 여러개의 세그먼트로 구성됩니다. 세그먼트 안에는 수많은 도큐먼트가 저장됩니다. 세그먼트는 다른 세그먼트와 별개로 완전히 독립적으로 동작하며, 별도로 검색할 수 있습니다. 인덱스를 변화시키는 방법은 두 가지가 존재합니다.
- 새로운 문서를 위한 세그먼트 만들기
- 이미 존재하는 세그먼트를 병합하기
세그먼트는 불변(Immutable) 특성을 지니고 있는데요. 다시 말하면 수정이 불가능하고, 읽기만 가능합니다. 이러한 특성으로 인해 멀티 스레드 환경에서 thread-safe 합니다. 세그먼트를 여러 스레드에서 공유해서 사용해도, 다른 스레드에 의해 변경되지 않을 것이기 때문에 언제나 그 결과가 예측 가능한 것이죠.
색인
IndexWriter가 Index File들을 생성하는 과정을 의미합니다.
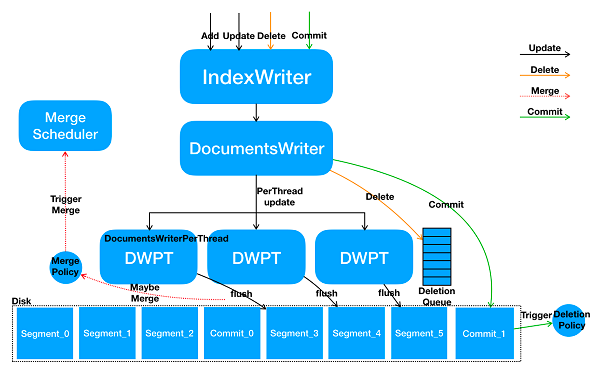 출처: https://www.alibabacloud.com/blog/lucene-indexwriter-an-in-depth-introduction_594673
출처: https://www.alibabacloud.com/blog/lucene-indexwriter-an-in-depth-introduction_594673
하나의 IndexWriter는 스레드별로 동작하는 DocumentsWriterPerThread들에게 세그먼트 파일 생성 작업을 위임하고, 해당 작업은 병렬로 수행됩니다.
출처: https://lucene.apache.org/core/3_0_3/fileformats.html#Index%20File%20Formats
문서정보
- 작성자:호준
- 링크:https://korjun1993.github.io/2024/01/17/lucene/
- 작성일: 2024-01-17