멀티테넌시
엘라스틱서치의 데이터는 여러 개의 분리된 인덱스들에 그룹으로 저장된다. 인덱스는 관계형 DB 모델에서의 데이터베이스로 대응되는데, 관계형 DB에서 다른 데이터베이스의 데이터를 검색하려면 별도의 커넥션을 생성해야 하는 것과 달리 엘라스틱서치에서는 데이터를 검색할 때 서로 다른 인덱스의 데이터를 바로 하나의 질의로 묶어서 검색하고 여러 검색 결과를 하나의 출력으로도 출력할 수 있다. 이러한 특징을 엘라스틱서치는 멀티 테넌시(Multi Tenancy)라고 한다.
게이트웨이
게이트웨이는 엘라스틱서치의 전체 클러스터의 상태를 저장하는 저장소다. 엘라스틱서치의 전체 클러스터가 종료된 후 재실행될 때 게이트웨이에 저장된 상태 값을 읽어 들여 노드와 인덱스 등에 대해 새로 설정하는데, 이 과정을 리커버리(recovery)라고 한다.
gateway.recover_after_nodes: 항목은 전체 클러스터가 시작되고 몇 개의 노드가 활성화됐을 때 리커버리를 시작할지 결정한다.gateway.recover_after_time: 지정된 개수의 노드가 활성화되고 얼마 동안의 시간을 기다린 후에 리커버리를 실행할지 결정한다.gateway.expected_nodes: 현재 엘라스틱서치 클러스터에 몇 개의 노드가 있는지 명시하고 설정된 개수만큼의 노드가 활성화되면 즉시 리커버리를 실행한다.
# gateway.recover_after_nodes: 1
# gateway.recover_after_time: 5m
위와 같이 설정하면 엘라스틱서치 클러스터가 시작되고 노드 1개가 실행된 후에 5분이 지나면 리커버리가 실행된다.
리커버리
리커버리는 엘라스틱서치의 전체 클러스터가 재실행되거나 노드, 인덱스 등이 추가/삭제될 때 설정된 클러스터의 상태를 유지하기 위해 데이터를 복사하고 재배치하는 활동이다. 설정할 수 있는 항목은 다음과 같다.
cluster.routing.allocation.node_initial_primaries_recoveries: 클러스터 재실행 후에 처음 리커버리가 실행될 때 몇 개의 샤드 및 복사본을 동시에 재배치하는 작업을 할지 결정한다.cluster.routing.allocation.node_concurrent_recoveries: 엘라스틱서치 운영 중 노드가 추가, 삭제되는 등 구조가 몇경될 때 몇 개의 샤드 및 복사본을 동시에 재배치하는 작업을 할지 설정한다.indices.recovery.max_bytes_per_sec: 초당 최대 얼만큼의 데이터를 리커버리 작업에 수행할 것인지 설정한다.indices.recovery.concurrent_streams: 노드 간 최대 몇 개까지의 데이터 교환 통신을 동시에 수행할 것인지 설정한다.
# cluster.routing.allocation
디스커버리
플러그인
엘라스틱서치는 플러그인을 설치해 여러 가지 편리한 기능을 추가로 사용할 수 있다. 플러그인은 bin/ 디렉터리의 plugin 프로그램을 사용해서 설치한다. 플러그인을 설치하는 명령어는 다음과 같다.
bin/plugin --install {org}/{user/component}/{version}
플러그인의 설치 파일 경로는 다음 위치 중 하나에 있어야 한다.
- http://download.elasticsearch.org/ 에 있는 경로와 파일
- http://search.maven.org/remotecontent?filepath= 에 있는 경로와 파일
- https://github.com/ 에 있는 경로와 파일
bin/plugin --install mobz/elasticsearch-head
위 명령을 통해 엘라스틱서치 시스템을 한눈에 보기 쉽게 다룰 수 있는 헤드(Head) 플러그인을 설치할 수 있다. 헤드 플러그인의 설치 파일은 깃허브의 mobz/elasticsearch-head에 있다. 플러그인을 설치하는 것 이외에도 플러그인과 관련된 다양한 명령어가 존재한다.
# 설치된 플러그인 목록 조회
bin/plugin --list
# 플러그인 삭제
bin/plugin --remove {플러그인명}
엘라스틱서치의 데이터 구조
엘라스틱서치의 데이터 구조는 인덱스(Index), 타입(Type), 도큐먼트(Document)의 단위로 이뤄져 있다. 도큐먼트는 엘라스틱서치의 데이터가 저장되는 최소 단위이며, 여러 개의 도큐먼트는 하나의 타입을 이루고, 다시 여러 개의 타입은 하나의 인덱스로 구성된다.
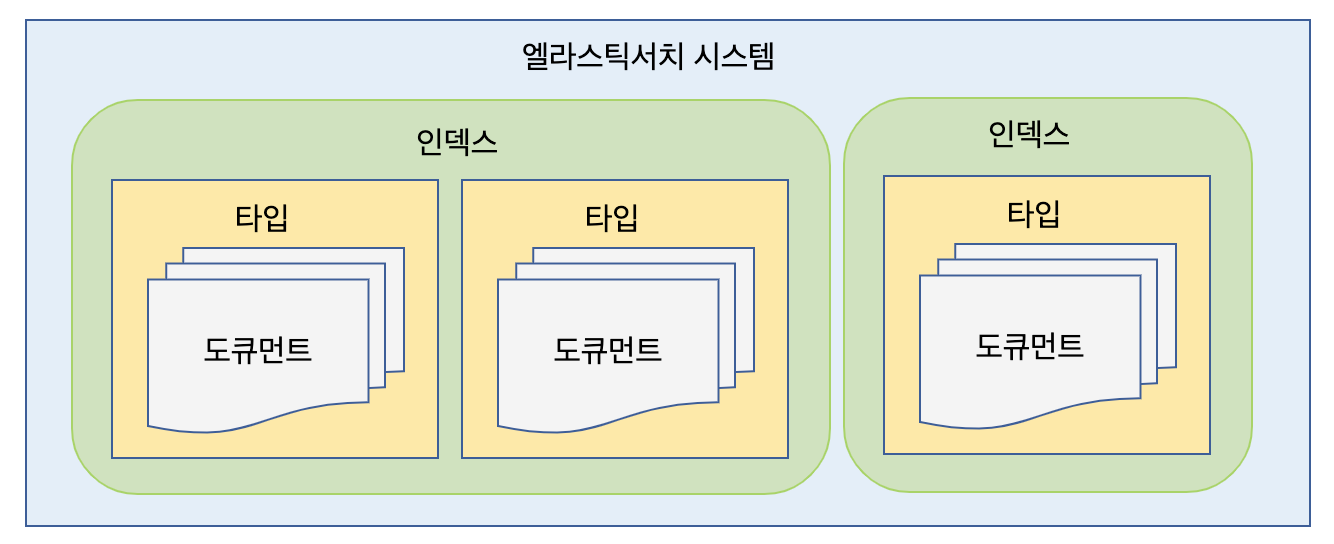
출처: 갓생사는 김초원의 개발 블로그
서로 다른 인덱스와 타입들은 각각 다른 공간에 저장되고 처리된다. 엘라스틱서치는 멀티테넌시를 지원하므로 _all 명령어나 와일드카드 질의 등으로 여러 개의 인덱스를 한꺼번에 묶어 검색하거나 처리할 수 있다.
보통 엘라스틱서치는 관계형 데이터베이스와 다음과 같이 비교된다.
| 관계형 DB | 엘라스틱서치 |
|---|---|
| 데이터베이스 | 인덱스 |
| 테이블 | 타입 |
| 행 | 도큐먼트 |
| 열 | 필드 |
| 스키마 | 매핑 |
엘라스틱서치 데이터 처리
1. 데이터 입력
엘라스틱서치 도큐먼트는 POST나 PUT HTTP 메서드를 사용해서 입력할 수 있다. books 라는 인덱스의 book 타입에 아이디가 1인 도큐먼트를 입력해보자. 이 도큐먼트는 4개의 필드(title, author, date, page)가 있으며, 내용은 다음과 같다.
PUT /books/book/1
{
"title": "Elasticsearch Guide",
"author": "kim",
"date": "2024-01-25",
"pages": 250
}
{"_index":"books","_type":"book","_id": "1","_version":1,"created":true}
_index는 books, _type은 book, _id는 1인 도큐먼트가 생성됐다는 메시지를 확인할 수 있다. 아무것도 없던 상태에서 도큐먼트를 처음으로 입력했기 때문에 인덱스와 타입이 자동으로 생성됐다. 이때는 created 필드가 true 로 나타난다.
도큐먼트 id를 생략하고 입력할 수도 있다. 이 경우 자동으로 임의의 id가 생성된다. 1-jtEDHgSHaoKrxK-oYDVw라는 임의의 id가 생성된 모습을 확인할 수 있다. 한 가지 주의해야 할 사항은 임의의 id로 도큐먼트를 생성하려면 POST 메서드를 이용해야 한다는 점이다.
POST /books/book
{
"title": "Elasticsearch Guide",
"author": "kim",
"date": "2024-01-25",
"pages": 250
}
{"_index":"books","_type":"book","_id": "1-jtEDHgSHaoKrxK-oYDVw","_version":1,"created":true}
2. 데이터 삭제
삭제는 도큐먼트, 타입, 인덱스 단위로 삭제할 수 있으며, DELETE 메서드를 이용한다.
DELETE /books/book/1
{"found":true,"_index":"books","_type":"book","_id":"1","_version":3}
삭제한 도큐먼트를 조회하면 결과에 found:false 값이 표시되고, 도큐먼트를 찾을 수 없음을 확인할 수 있다.
GET /books/book/1
{"_index":"books","_type":"book","_id":"1","found":false}
도큐먼트 데이터를 삭제하더라도 도큐먼트의 메타 정보는 여전히 남아있다. 도큐먼트의 삭제는 도큐먼트가 실제로 삭제되는 것이 아니라 도큐먼트의 _source에 입력된 데이터 값이 빈 값으로 업데이트되고 검색되지 않게 상태가 변경되는 것으로 이해하는 것이 편하다.
DELETE 메서드를 사용한 삭제 명령은 타입과 인덱스 단위로도 사용할 수 있다. 데이터를 삭제할 때 명령에 /books/book과 같이 입력하면 /books/book 타입에 있는 모든 도큐먼트가 일괄 삭제된다. 이때는 도큐먼트의 메타 정보까지 모두 삭제된다.
3. 데이터 업데이트
엘라스틱서치에서는 입력된 도큐먼트를 수정할 수 있는 _update API를 제공한다. 도큐먼트 데이터의 업데이트는 _update API의 매개 변수인 doc와 script를 이용해서 데이터를 제어할 수 있다.
- doc: 도큐먼트에 새로운 필드를 추가하거나 기존 필드 값을 변경할 때
- script: 복잡한 프로그래밍 기법을 사용해서 입력된 내용에 따라 필드의 값을 변경할 때
_update API는 POST 메서드를 사용하며, 다음 URI처럼 doc 매개 변수를 사용해서 도큐먼트에 category 필드를 추가할 수 있다.
POST my_index/_update/1
{
"doc": {
"category": "ICT"
}
}
참고 문서
- https://lucene.apache.org/core/3_0_3/fileformats.html#Index%20File%20Formats
- 시작하세요! 엘라스틱서치 - 김종민 지음
문서정보
- 작성자:호준
- 링크:https://korjun1993.github.io/2024/01/25/elasticsearch/
- 작성일: 2024-01-25