목적
- 상품 인덱스 샤드 구성을 최적화한다.
- 하위 요소를 변화시키면서 부하 스크립트(테스트 시나리오 코드)를 통해 성능을 측정해보고, 최적의 값을 운영 환경에 적용한다.
- 샤드 크기
- 샤드 개수
- 데이터노드 개수
실험: Step1 - 샤드크기 조정하기
실험 목적
- 상품 인덱스로 유입되는 모든 쿼리의 응답속도(P90 Latency)가 50ms 이하를 만족시킬 수 있도록 단일 샤드의 크기를 조정한다.
실험 방법
- 운영 중인 데이터노드와 동일한 스펙의 노드 1개를 준비한다.
- 1️⃣ 에서 준비한 노드에 단일 샤드로 구성된 인덱스를 구축한다.
- 샤드의 크기를 키워가며 주요 쿼리들의 응답속도를 측정한다.
실험 결과

결론
- 현재 상품 인덱스의 샤드 크기는 12gb이다.
- 상품 검색 쿼리들의 응답속도를 50ms 이하로 만들려면 샤드 크기를 약 5.5gb 이하로 유지해야한다.
실험: Step2 - 샤드 크기 조정에 따른 단일 노드의 CPU 사용 관찰
실험 목적
- step1을 통해 상품 인덱스의 샤드 크기를 약 5.5gb 이하로 유지해야함을 알아냈다.
- 현재 샤드는 12gb 5개로 구성되어있다.
- 5gb 12개로 변경한 후, 부하 테스트를 실시했을 때, 노드의 CPU 사용률이 실제로 얼만큼 증가하는지 살펴본다.
실험 방법
- 운영 중인 데이터노드와 동일한 스펙의 노드 2개(A, B) 를 준비한다.
- 노드A에 상품 인덱스 샤드(12gb,5개)를 만들고, 노드 B에 상품 인덱스 샤드(5gb,12개)를 만든다.
- 노드A, 노드B에 부하 테스트를 수행하고, CPU 사용률을 비롯한 각종 지표를 비교한다.
실험 결과
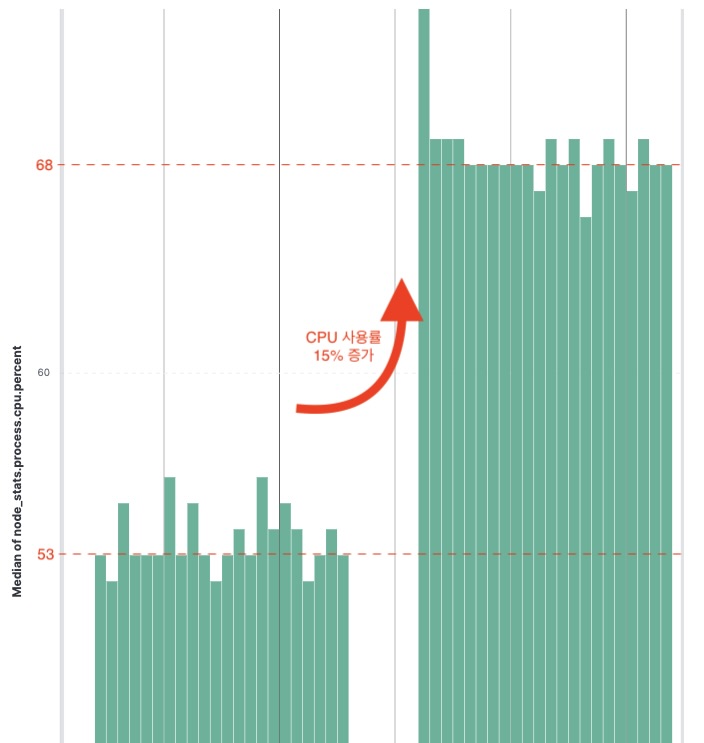
결론
- 노드의 샤드 개수(단일검색엔진) 증가로 인해 검색 행위에 필요한 스레드 증가한다.
- 노드의 CPU 사용률이 증가한다.
실험: step3 - 데이터노드 증편에 따른 클러스터의 CPU 사용률 관찰
실험 목적
- 상품 인덱스 샤드를 5gb x 12개로 구성했을 때, 기존 CPU 사용률을 유지하려면, 데이터노드를 몇개 추가해야하는지 알아낸다.
실험 방법
- 운영 환경의 클러스터와 동일한 스펙의 클러스터를 준비한다.
- 클라이언트 노드 1대
- 데이터노드 3대
- 인덱스를 기존/실험군 버전을 나눠 구축한다.
- 기존 샤드: 12gb x 5
- 실험군 샤드수: 5gb x 12
- CPU 사용률을 비롯한 매트릭이 안정될 때 까지 데이터노드 수를 증축시켜가며 부하 테스트를 반복한다. (실험 중단)
부하 스크립트
- 시간 & 인덱스별로 search, indexing 요청량이 상이하다.
- 평일 오후 20~22시의 요청량을 부하스크립트의 부하율을 결정한다.
| 쿼리 이름 | 구분 | 부하량 | 설명 |
|---|---|---|---|
| category-query | search | 4/s | 상품 카테고리 검색 쿼리 |
| product-search | search | 32/s | 상품 통합 검색 쿼리 |
| scatter-price-query | search | 4/s | 상품 시세 집계 쿼리 |
| main-recent-products | search | 27/s | 최신 상품 검색 쿼리 |
| last-view-products | search | 27/s | 최근 본 상품 검색 쿼리 |
| mystore-products | search | 34/s | 나의 상품 검색 쿼리 |
| product-update | indexing | 6/s | 상품 정보 증분 색인 쿼리 |
실험 결과
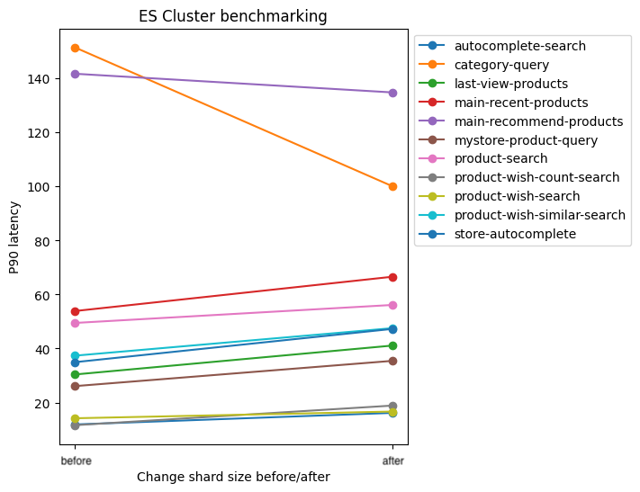
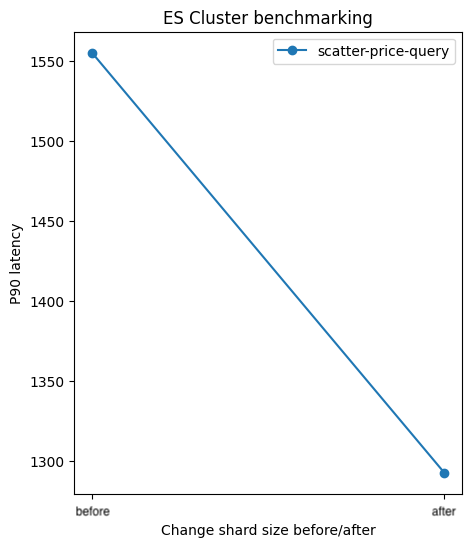
- 데이터 노드 수를 현재와 동일하게 둘 경우, 기존/실험군 인덱스에 대한 부하 테스트 결과는 아래와 같다.
부하 스크립트 벤치마킹
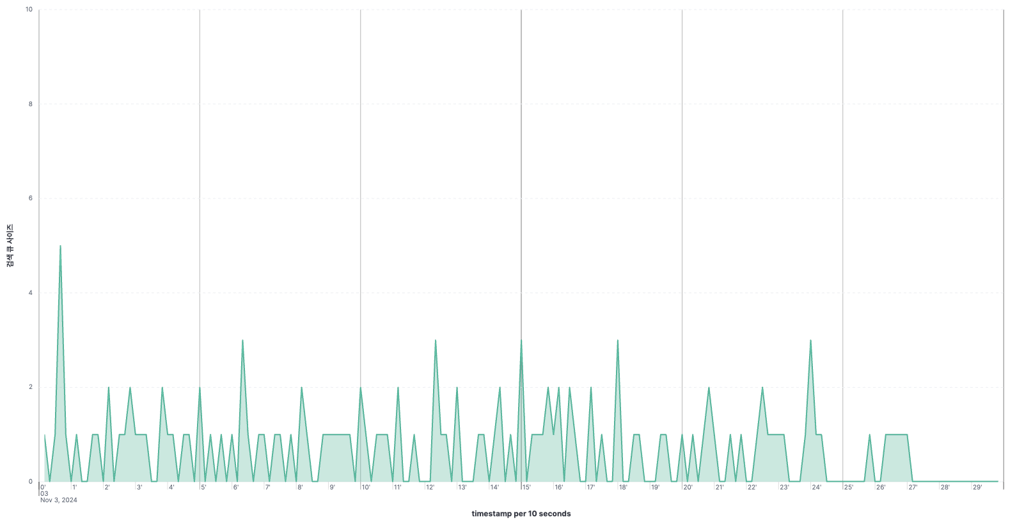
검색 큐 사이즈
| 기존 | 실험군 |
|---|---|
 | 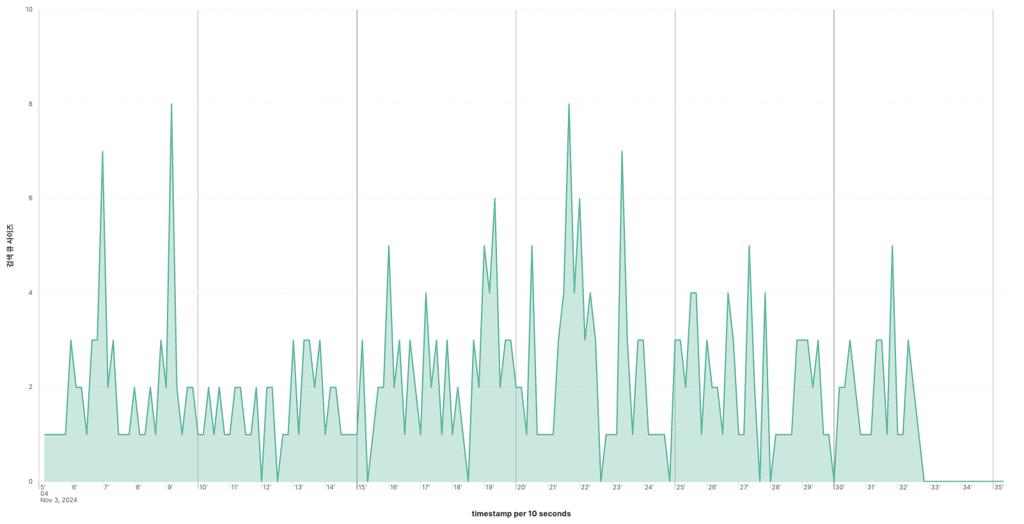 |
실험 결과에 대한 해석
- 샤드의 크기는 줄었으나, 노드에 할당된 샤드 수가 증가함으로 인해, Task Queue Waiting time 증가한다.
- https://brunch.co.kr/@alden/39 참고
- 노드가 기존에 비해 더 많은 문서를 읽으므로 Heap 사용량이 증가하며, GC time도 증가한다.
- Total Young Gen GC time: 13.338s → 46.423s
- Total Young Gen GC count: 1469 → 1842
- 1+2번의 영향으로 인해 대부분의 쿼리는 느려진다.
- 단, 1+2번의 영향보다 샤드 크기 감소의 영향이 큰 쿼리는 빨라진다.
- 검색 결과가 많은 쿼리
- 정렬 또는 집계 로직이 포함된 쿼리
- 결론적으로, 샤드의 크기는 줄었지만 노드당 처리 쿼리가 많아진 만큼 데이터 노드 수 증편이 필요하다.
최종 결론
- 샤드 크기를 줄이고 개수를 늘리려면, 데이터노드의 증편이 필요하다.
- 대부분의 쿼리는 샤드 크기에 민감하게 반응하지 않는다.
- 카테고리 검색 쿼리, 평균 가격 집계 쿼리 등 소수의 샤드 크기에 영향을 받는 쿼리 때문에 데이터노드를 증편하는 것은 비효율적이다.
- 샤드크기에 영향을 받는 쿼리를 먼저 개선하자.
참고 자료
- https://brunch.co.kr/@alden/39
- https://www.elastic.co/guide/en/elasticsearch/guide/current/capacity-planning.html
- https://www.elastic.co/kr/blog/benchmarking-and-sizing-your-elasticsearch-cluster-for-logs-and-metrics
- https://www.elastic.co/guide/en/elasticsearch/reference/current/size-your-shards.html
- https://www.elastic.co/pdf/elasticsearch-sizing-and-capacity-planning.pdf
- https://stackoverflow.com/questions/36058148/how-to-diagnose-elasticsearch-search-queue-growth
문서정보
- 작성자:호준
- 링크:https://korjun1993.github.io/2024/11/22/capacity-planning/
- 작성일: 2024-11-22